
 Índice
ÍndicePrecisión en función de las predicciones ♦ KNN - Machine Learning - Python
Página 1 de 1.
![]()
 Precisión en función de las predicciones ♦ KNN - Machine Learning - Python
Precisión en función de las predicciones ♦ KNN - Machine Learning - Python
Manfenix Miér Oct 18, 2023 12:19 pm
# Librerías usadas
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_score
# Carga del dataset
dataset = datasets.load_breast_cancer()
X = dataset.data
y = dataset.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Creación de listas para almacenar las precisiones y valores de n_neighbors
precisions_p1 = []
precisions_p2 = []
n_neighbors_values = []
# Se hacen un total de 50 predicciones, variando los vecinos cercanos cada 10 predicciones, para p igual a 1
for i in range(50):
# Se cambia el valor de n_neighbors cada 10 predicciones
if i % 10 == 0:
n_neighbors = 2 + i*11 // 11 # Comienza con n_neighbors = 2 y aumenta en cada ciclo 11 unidades
# Se toma p igual a 1
p = 1
# Crear el modelo KNeighborsClassifier con los valores actuales de n_neighbors y p
algoritmo = KNeighborsClassifier(n_neighbors=n_neighbors, metric='minkowski', p=p)
# Entrenar el modelo
algoritmo.fit(X_train, y_train)
# Realizar predicciones en el conjunto de prueba
y_pred = algoritmo.predict(X_test)
# Calcular la precisión y guardarla en la lista correspondiente
precision = precision_score(y_test, y_pred)
precisions_p1.append(precision)
# Guardar el valor actual de n_neighbors
n_neighbors_values.append(n_neighbors)
# Restaurar el valor inicial de n_neighbors
n_neighbors = 2
# Realizar un total de 50 predicciones con p igual a 2, cambiando el valor de los vecinos cercanos cada 10 predicciones
for i in range(50):
# Cambiar el valor de n_neighbors cada 10 predicciones
if i % 10 == 0:
n_neighbors = 2 + i*11 // 11 # Comienza con n_neighbors = 2 y aumenta en cada ciclo 11 unidades
# Tomar p igual a 2
p = 2
# Crear el modelo KNeighborsClassifier con los valores actuales de n_neighbors y p
algoritmo = KNeighborsClassifier(n_neighbors=n_neighbors, metric='minkowski', p=p)
# Entrenar el modelo
algoritmo.fit(X_train, y_train)
# Realizar predicciones en el conjunto de prueba
y_pred = algoritmo.predict(X_test)
# Calcular la precisión y guardarla en la lista correspondiente
precision = precision_score(y_test, y_pred)
precisions_p2.append(precision)
#Graficar las precisiones indidivuales en función del número de predicciones
plt.figure(figsize=(10, 6))
plt.plot(range(1, 51), precisions_p1, marker='o', linestyle='-', color='b', label='Precisions p=1')
plt.plot(range(1, 51), precisions_p2, marker='o', linestyle='-', color='r', label='Precisions p=2')
plt.xlabel('Número de Predicciones')
plt.ylabel('Precisión')
plt.title('Precisión en función del número de predicciones')
plt.legend() # Agregar una leyenda para identificar las líneas
plt.grid(True)
plt.show()
# Imprimir los valores de n_neighbors utilizados
print("Valores de n_neighbors utilizados:", n_neighbors_values)
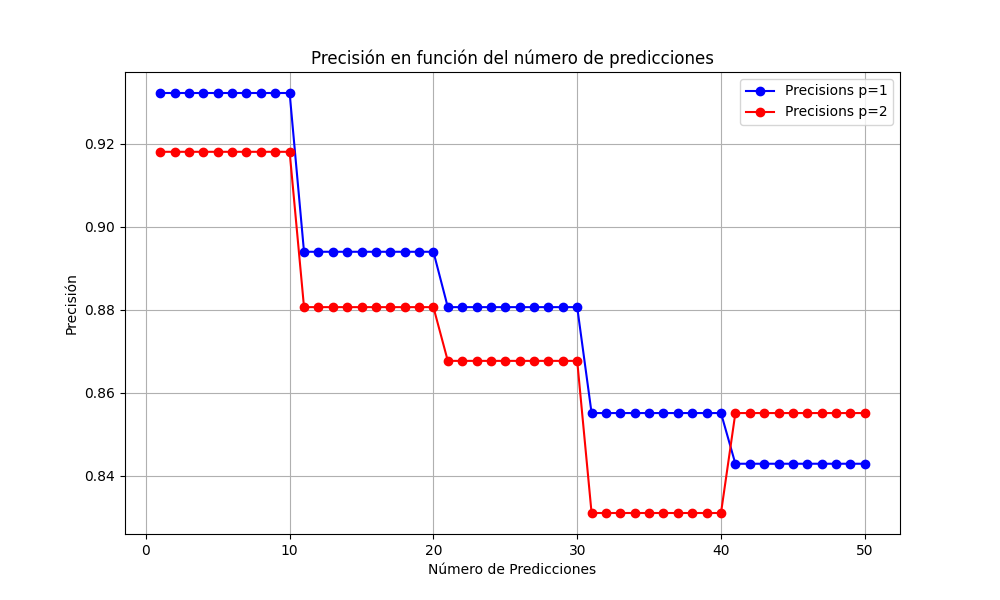
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_score
# Carga del dataset
dataset = datasets.load_breast_cancer()
X = dataset.data
y = dataset.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Creación de listas para almacenar las precisiones y valores de n_neighbors
precisions_p1 = []
precisions_p2 = []
n_neighbors_values = []
# Se hacen un total de 50 predicciones, variando los vecinos cercanos cada 10 predicciones, para p igual a 1
for i in range(50):
# Se cambia el valor de n_neighbors cada 10 predicciones
if i % 10 == 0:
n_neighbors = 2 + i*11 // 11 # Comienza con n_neighbors = 2 y aumenta en cada ciclo 11 unidades
# Se toma p igual a 1
p = 1
# Crear el modelo KNeighborsClassifier con los valores actuales de n_neighbors y p
algoritmo = KNeighborsClassifier(n_neighbors=n_neighbors, metric='minkowski', p=p)
# Entrenar el modelo
algoritmo.fit(X_train, y_train)
# Realizar predicciones en el conjunto de prueba
y_pred = algoritmo.predict(X_test)
# Calcular la precisión y guardarla en la lista correspondiente
precision = precision_score(y_test, y_pred)
precisions_p1.append(precision)
# Guardar el valor actual de n_neighbors
n_neighbors_values.append(n_neighbors)
# Restaurar el valor inicial de n_neighbors
n_neighbors = 2
# Realizar un total de 50 predicciones con p igual a 2, cambiando el valor de los vecinos cercanos cada 10 predicciones
for i in range(50):
# Cambiar el valor de n_neighbors cada 10 predicciones
if i % 10 == 0:
n_neighbors = 2 + i*11 // 11 # Comienza con n_neighbors = 2 y aumenta en cada ciclo 11 unidades
# Tomar p igual a 2
p = 2
# Crear el modelo KNeighborsClassifier con los valores actuales de n_neighbors y p
algoritmo = KNeighborsClassifier(n_neighbors=n_neighbors, metric='minkowski', p=p)
# Entrenar el modelo
algoritmo.fit(X_train, y_train)
# Realizar predicciones en el conjunto de prueba
y_pred = algoritmo.predict(X_test)
# Calcular la precisión y guardarla en la lista correspondiente
precision = precision_score(y_test, y_pred)
precisions_p2.append(precision)
#Graficar las precisiones indidivuales en función del número de predicciones
plt.figure(figsize=(10, 6))
plt.plot(range(1, 51), precisions_p1, marker='o', linestyle='-', color='b', label='Precisions p=1')
plt.plot(range(1, 51), precisions_p2, marker='o', linestyle='-', color='r', label='Precisions p=2')
plt.xlabel('Número de Predicciones')
plt.ylabel('Precisión')
plt.title('Precisión en función del número de predicciones')
plt.legend() # Agregar una leyenda para identificar las líneas
plt.grid(True)
plt.show()
# Imprimir los valores de n_neighbors utilizados
print("Valores de n_neighbors utilizados:", n_neighbors_values)


Manfenix- Admin
- Mensajes : 3440
Fecha de inscripción : 20/03/2010
Localización : Argentina -

![]()
![]()
![]()
Página 1 de 1.
Permisos de este foro:
No puedes responder a temas en este foro.|
|
|